Accelerate Software and Projects
Machine learning has become an indispensable tool, but implementing it brings challenges for researchers.
Here, you can find highlights from our collaborations with researchers across the university. These projects feature new research findings, methodologies, and custom software solutions.
Our role varies significantly: sometimes we provide targeted assistance—adding features to existing tools or solving specific technical challenges—while other times we're involved from the ground up, contributing to research design and methodology development throughout the entire process. But every collaboration is driven by domain expert researchers.
To engage us for your project, please get in touch!
Otherwise, please checkout some of the projects that we've worked on!
NETTS
-
Caroline Nettekoven
Psychiatry
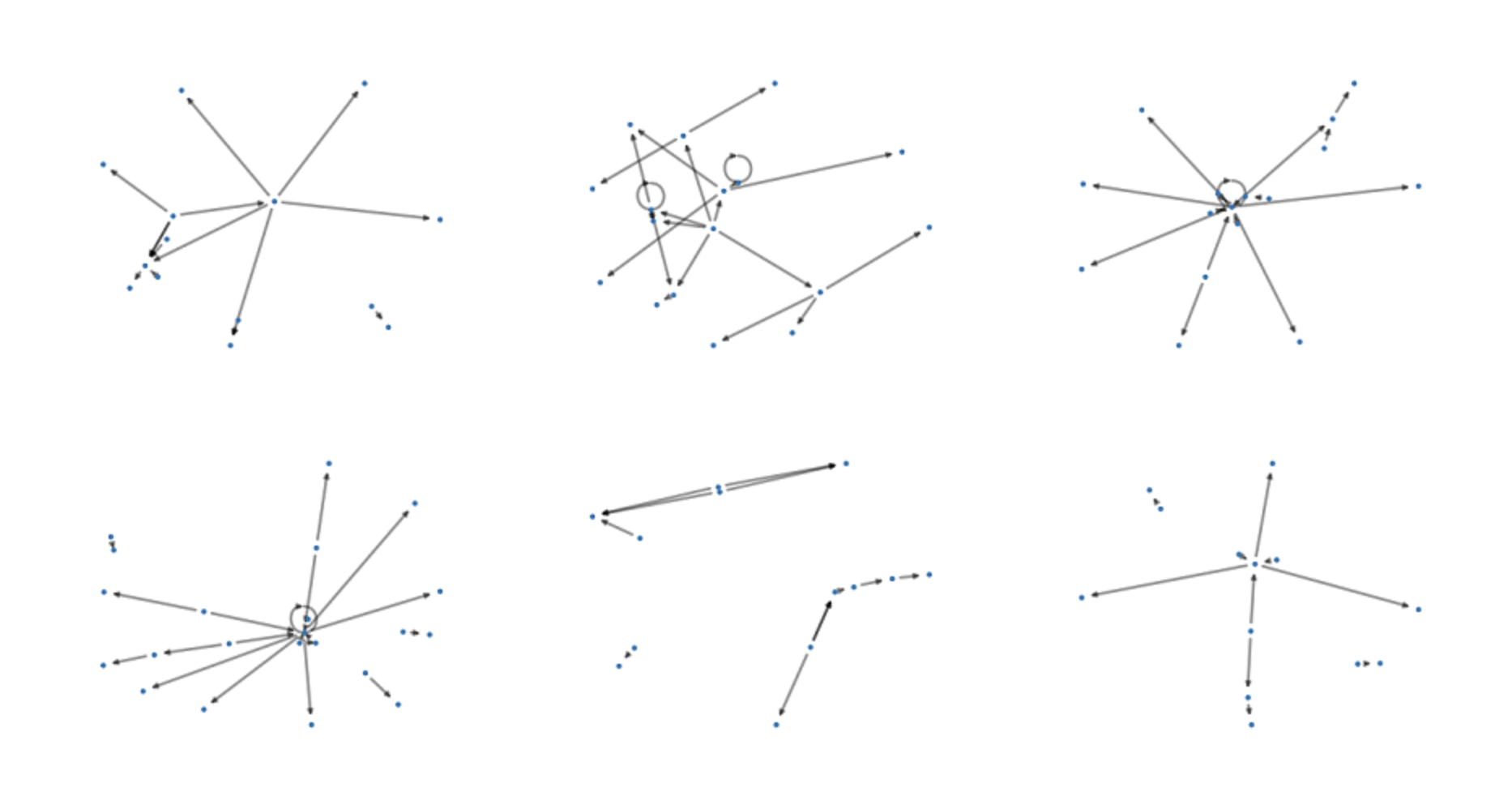
NETTS constructs networks from a speech transcript that represent the content of what the speaker said. The idea here is that the nodes in the network show the entities that the speaker mentioned, like a cat, a house, etc. (usually nouns). And the edges of the network show the relationships between the entities. We called these networks semantic speech networks.
Conceptual Cartography
-
Nina Haket
Modern and Medieval Languages
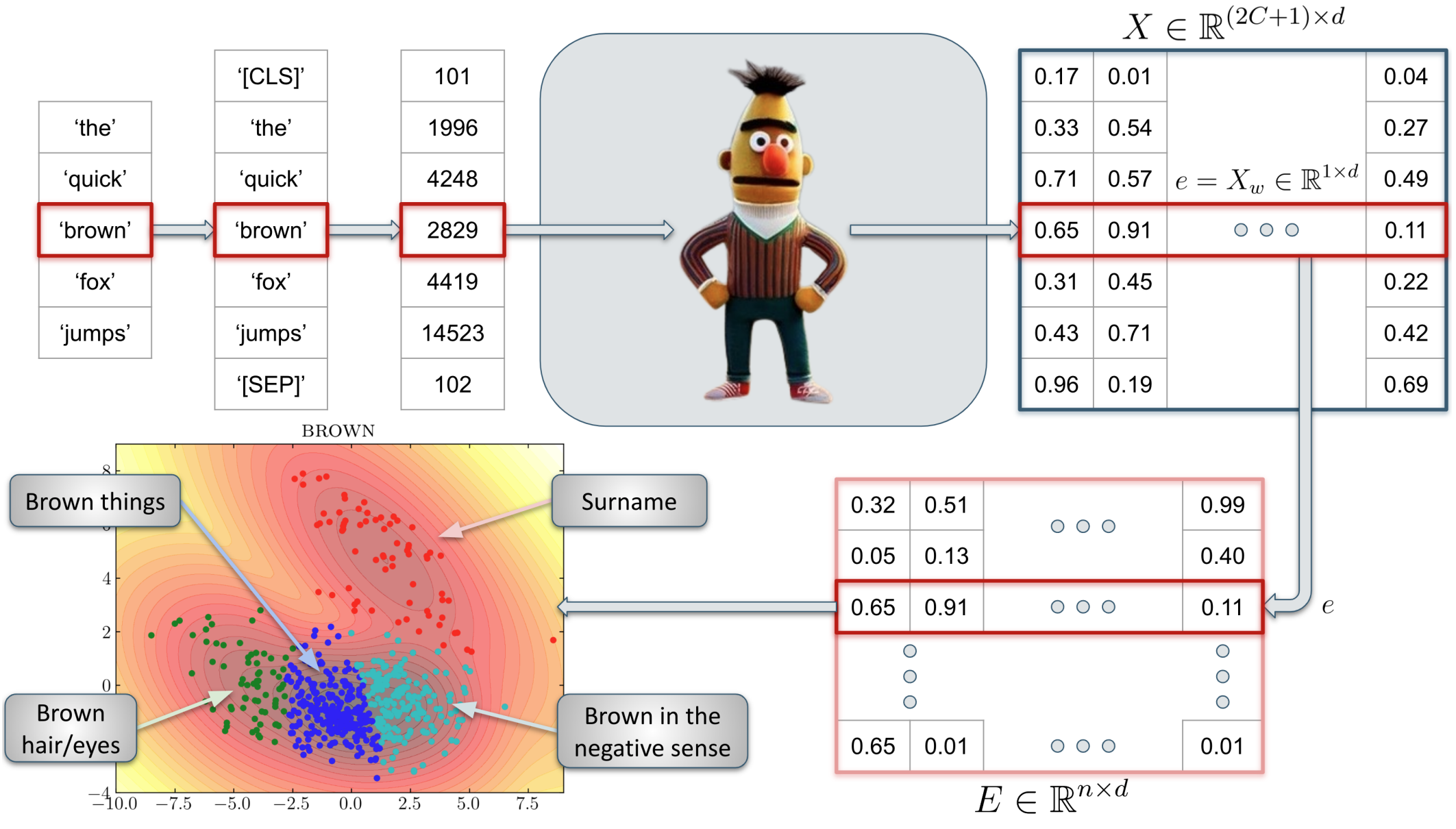
Philosophers worry that the way we use everyday language may prevent us from accurately portraying the world, or even undermine our ability to think clearly. Nina studies conceptual engineering and is interested in changing some aspects of natural language that are problematic or defective. Changes in language can be difficult to analyse, but Nina's approach uses Large Language Models (LLMs) to identify how words are used, drawing upon data from conversations between real people, and therefore taking a step away from introspective thinking about words.
Speaking with our Sources
-
Jacob Forward
History

One of the biggest unresolved methodological and theoretical problems facing the history discipline today is source abundance. The haystack of information hiding potentially salient needles of evidence has grown and continues to grow at an exponential rate. Although awareness of this problem is widespread, few solutions exist. AI large language models (LLMs) may offer a path forward. This work presents a research project on experimental applications of LLMs to historical research workflows, focusing on how LLMs can tackle the source abundance problem by enhancing traditional discourse analysis. The project’s case study focuses on two large corpora (over 3 million words each) of spoken addresses and remarks from presidents Franklin D. Roosevelt and Ronald Reagan, digitized by the American Presidency Project.
This is a work in progress, and more details will be available later on this year.
PicoLM
-
Richard Diehl Martinez
Computer Science and Technology

Richard developed Pico with other Master’s and PhD students from the NLP group, alongside researchers from the Accelerate Programme. Pico is a versatile language modelling framework that helps AI researchers develop small, well-founded, and high-performing models that require fewer computing resources. It’s designed to support training on small, bespoke or confidential datasets. This is useful for researchers and companies because model weights can be stored and managed locally without requiring internet access, ensuring users retrain full control of the model and data.
Small World Propensity
-
Ryan Daniels
Computer Science and Technology
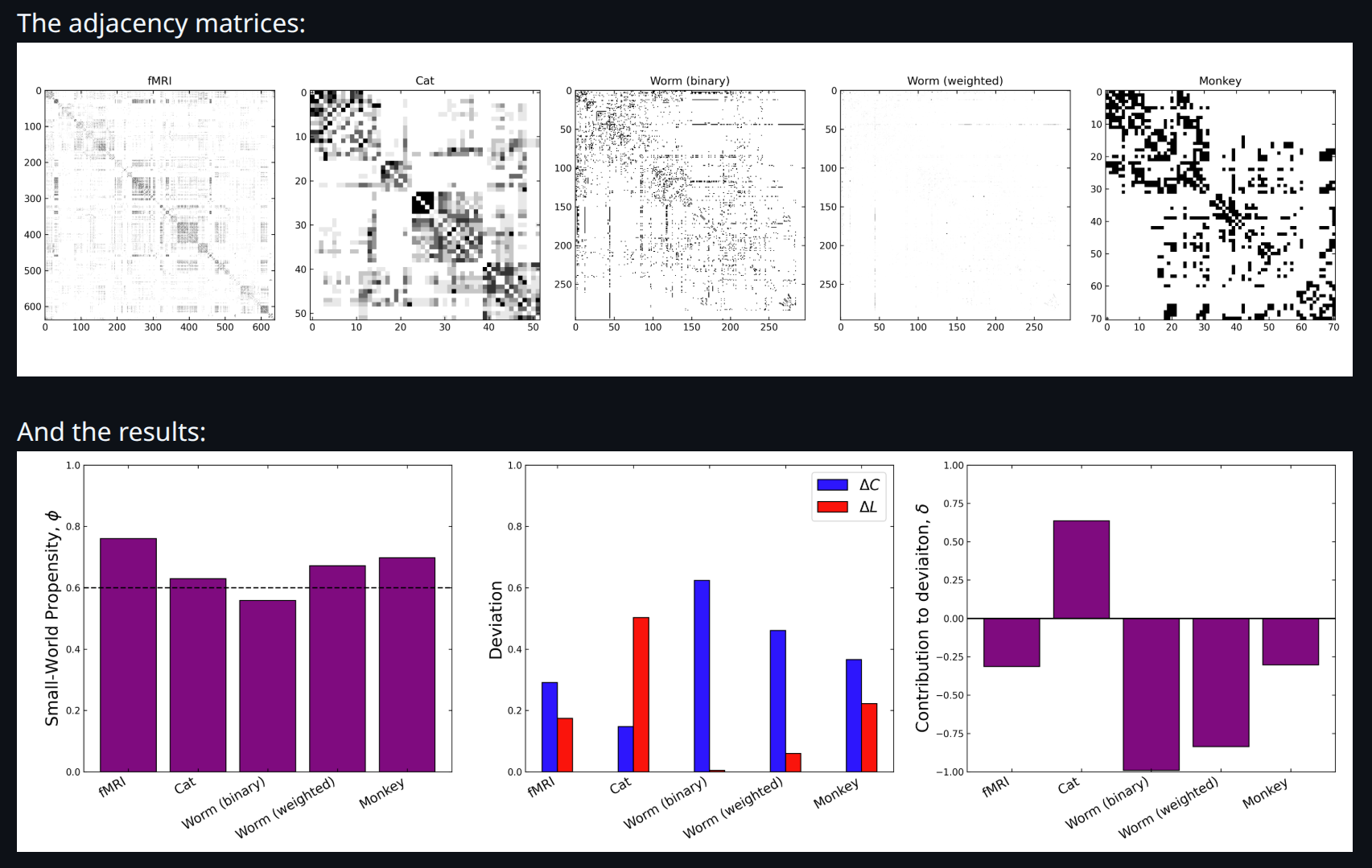
Small world networks occur everywhere in nature, and there are a number of methods used to measure the small world nature of graphs. However, most techniques are density dependent and do not take into account edge weights. To overcome these limitations, Muldoon et al developed the small world propensity measure in MATLAB. Modern data pipelines however, are often written in Python. In order to integrate the SWP measure into python workflows, we translated the MATLAB implementation into Python, preserving the results and performance.
Patient presentations with LLMs
-
Brittany Cutten
Clinical Medicine
Following some changes to the clinical school's Learning Management System (LMS) some resources needed to be reinstated, one of which was a collection of pages intended to help students structure their approach to common clinical scenarios, such as 'chest pain', abdominal mass' etc. - common symptoms that patients present with to a medical professional.
This content allows students to think in terms of symptoms, not just diagnoses, which reflects how patients actually present in real life.
Unfortunately, student feedback indicated that the content was poorly formatted. Trying to reformat all 176 patient presentations would take days. Fortunately, this sounds like a job for an LLM...
LLM Performance on Obfuscated Tasks
-
Radzim Sendyka
Computer Science and Technology
This work investigates the ability of large language models (LLMs) to recognise and solve tasks which have been obfuscated beyond recognition. Focusing on competitive programming and benchmark tasks (LeetCode and MATH), it compares performance across multiple models and obfuscation methods, such as noise and redaction.